







Cách thực hiện Web Scraping với Puppeteer và NodeJS | Hướng dẫn Puppeteer

Anh Tuan
Data Science Expert
12-Nov-2025

Web scraping là một kỹ thuật mạnh mẽ được sử dụng để trích xuất dữ liệu từ các trang web. Trong hướng dẫn này, chúng ta sẽ khám phá cách thực hiện web scraping bằng Puppeteer và Node.js, hai công nghệ phổ biến trong hệ sinh thái phát triển web. Puppeteer là một thư viện Node.js cung cấp giao diện cấp cao để điều khiển trình duyệt Chrome hoặc Chromium không giao diện. Nó cho phép chúng ta tự động hóa các hành động trình duyệt, điều hướng qua các trang web và trích xuất dữ liệu mong muốn. Bằng cách kết hợp Puppeteer với tính linh hoạt của Node.js, chúng ta có thể xây dựng các giải pháp web scraping mạnh mẽ và hiệu quả. Hãy cùng tìm hiểu các bước liên quan đến việc trích xuất dữ liệu từ các trang web bằng Puppeteer.
Puppeteer là gì?
Puppeteer là một khung phần mềm tiên tiến giúp các nhà kiểm thử thực hiện kiểm tra trình duyệt không giao diện với Google Chrome. Với kiểm tra Puppeteer, các nhà kiểm thử có thể thực thi các lệnh JavaScript để tương tác với các trang web, bao gồm các hành động như nhấp vào liên kết, điền biểu mẫu và gửi nút.
Do Google phát triển, Puppeteer là một thư viện Node.js cho phép kiểm soát Chrome không giao diện một cách liền mạch thông qua giao thức DevTools. Nó cung cấp nhiều giao diện cấp cao giúp tự động hóa kiểm tra, phát triển tính năng trang web, gỡ lỗi, kiểm tra phần tử và phân tích hiệu năng.
Với Puppeteer, bạn có thể sử dụng (Chrome không giao diện) Chromium hoặc Chrome để mở trang web, điền biểu mẫu, nhấp nút, trích xuất dữ liệu và nói chung thực hiện mọi hành động mà một người dùng có thể làm khi sử dụng máy tính. Điều này khiến Puppeteer trở thành một công cụ mạnh mẽ cho web scraping, nhưng cũng cho việc tự động hóa các quy trình phức tạp trên web. Việc hiểu rõ Puppeteer và khả năng của nó là vô giá đối với các nhà kiểm thử và nhà phát triển trong môi trường phát triển web hiện đại.
Những lợi ích khi sử dụng Puppeteer cho web scraping là gì?
Axios và Cheerio là các lựa chọn tuyệt vời để trích xuất dữ liệu bằng JavaScript. Tuy nhiên, điều này đặt ra hai vấn đề: thu thập nội dung động và phần mềm chống trích xuất dữ liệu. Vì Puppeteer là trình duyệt không giao diện, nó không gặp vấn đề gì khi trích xuất nội dung động.
Ngoài ra, Puppeteer cung cấp một loạt lợi ích quan trọng cho web scraping:
-
Tự động hóa trình duyệt không giao diện: Với Puppeteer, bạn có thể điều khiển trình duyệt Chrome không giao diện một cách lập trình, cho phép tự động hóa các hành động trình duyệt như nhấp chuột, cuộn trang, điền biểu mẫu và trích xuất dữ liệu mà không cần cửa sổ trình duyệt hiển thị.
-
Tính năng đầy đủ của Chrome và thao tác DOM: Puppeteer cung cấp quyền truy cập vào toàn bộ tính năng của Chrome, phù hợp để trích xuất các trang web hiện đại có nội dung dựa trên JavaScript. Bạn có thể dễ dàng tương tác với các phần tử trang, thay đổi thuộc tính và thực hiện các hành động như nhấp nút hoặc gửi biểu mẫu.
-
Tương tác người dùng được mô phỏng và thu thập sự kiện: Puppeteer cho phép bạn mô phỏng các hành động của người dùng và thu thập các yêu cầu mạng và phản hồi. Điều này giúp trích xuất các trang web yêu cầu đầu vào người dùng hoặc tải nội dung động thông qua yêu cầu AJAX hoặc WebSocket.
-
Khả năng hiệu suất và gỡ lỗi: Động cơ Chrome được tối ưu hóa của Puppeteer đảm bảo hiệu suất trích xuất cao, và tích hợp với DevTools mang lại khả năng gỡ lỗi và kiểm tra mạnh mẽ. Bạn có thể gỡ lỗi các trang web, ghi nhật ký các thông báo trong bảng điều khiển, theo dõi hoạt động mạng và phân tích các chỉ số hiệu suất.
Trong các hướng dẫn tiếp theo, tôi sẽ khám phá quy trình trích xuất dữ liệu web bằng Puppeteer và Node.js, cùng với việc tích hợp giải pháp giải CAPTCHA tiên tiến, CapSolver, để vượt qua một trong những thách thức lớn nhất gặp phải trong quá trình trích xuất dữ liệu.
Mã thưởng
Một mã thưởng cho các giải pháp CAPTCHA hàng đầu; CapSolver : WEBS. Sau khi sử dụng, bạn sẽ nhận thêm 5% thưởng sau mỗi lần nạp tiền, không giới hạn.

Cách giải CAPTCHA trong Puppeteer bằng CapSolver khi trích xuất dữ liệu web
Mục tiêu sẽ là giải CAPTCHA tại recaptcha-demo.appspot.com bằng CapSolver.
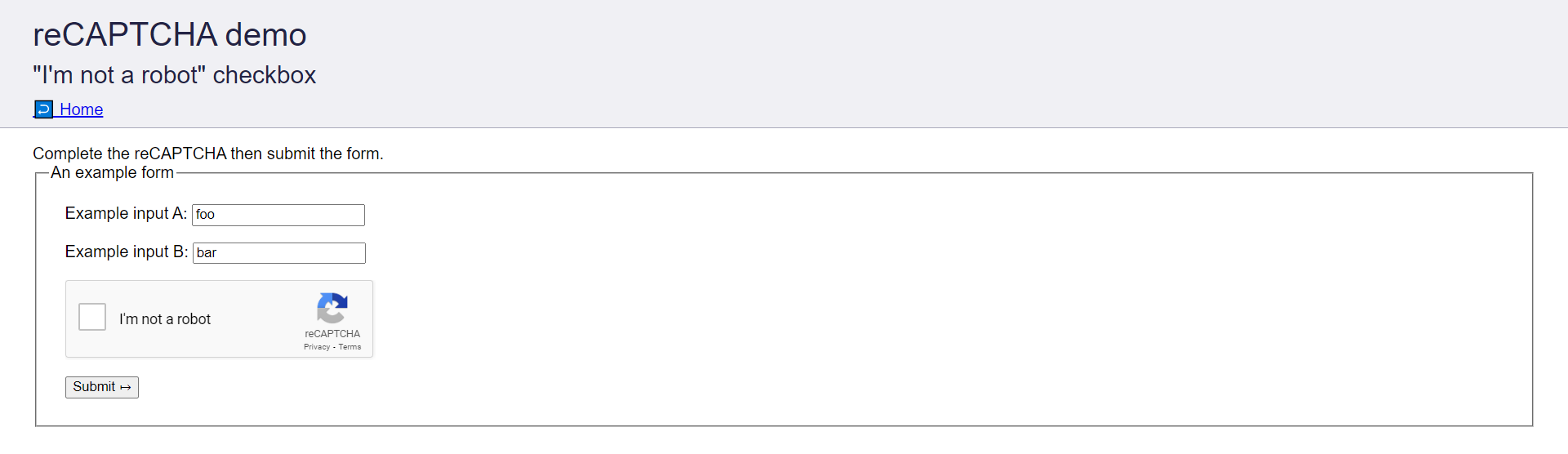
Trong hướng dẫn này, chúng ta sẽ thực hiện các bước sau để giải CAPTCHA trên:
- Cài đặt các phụ thuộc cần thiết.
- Tìm khóa trang của Form CAPTCHA.
- Thiết lập CapSolver.
- Giải CAPTCHA.
Cài đặt các phụ thuộc cần thiết
Để bắt đầu, chúng ta cần cài đặt các phụ thuộc sau cho hướng dẫn này:
- capsolver-python: SDK Python chính thức để tích hợp dễ dàng với API CapSolver.
- pyppeteer: pyppeteer là phiên bản Python của Puppeteer.
Cài đặt các phụ thuộc này bằng cách chạy lệnh sau:
python -m pip install pyppeteer capsolver-pythonBây giờ, tạo một tệp có tên main.py nơi chúng ta sẽ viết mã Python để giải CAPTCHA.
bash
touch main.pyTìm khóa trang của Form CAPTCHA
Khóa trang là một định danh duy nhất do Google cung cấp để xác định duy nhất mỗi CAPTCHA.
Để giải CAPTCHA, cần gửi khóa trang đến CapSolver.
Hãy tìm khóa trang của Form CAPTCHA bằng các bước sau:
- Truy cập Form CAPTCHA.
- Mở Chrome Dev Tools bằng cách nhấn
Ctrl/Cmd+Shift+I. - Chuyển đến tab
Elementsvà tìmdata-sitekey. Sao chép giá trị thuộc tính.
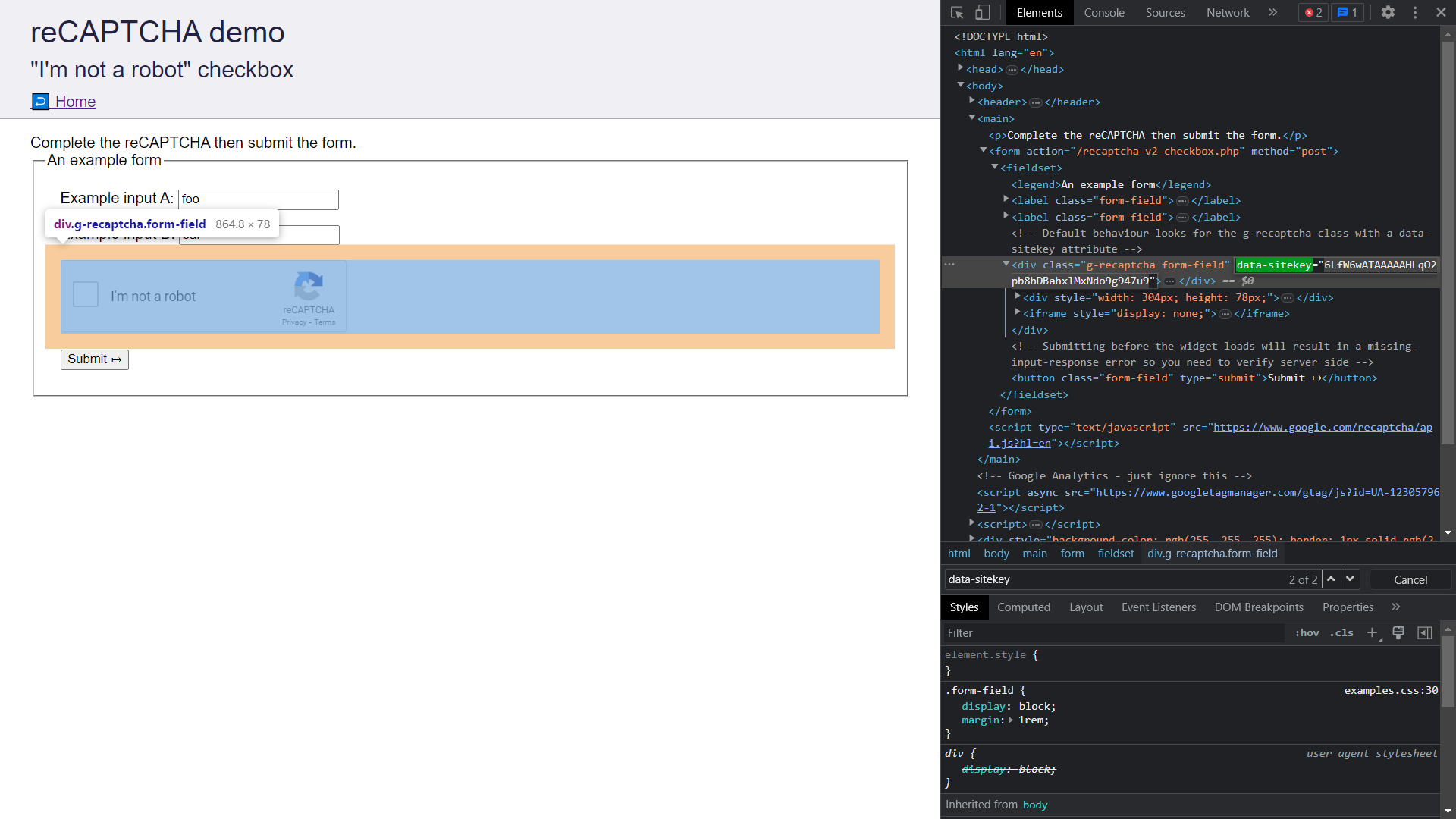
- Lưu khóa trang tại một nơi an toàn vì nó sẽ được sử dụng trong phần sau khi chúng ta gửi CAPTCHA đến CapSolver.
Thiết lập CapSolver
Để giải CAPTCHA bằng CapSolver, bạn cần tạo tài khoản CapSolver, nạp tiền vào tài khoản và lấy khóa API. Làm theo các bước sau để thiết lập tài khoản CapSolver của bạn:
-
Đăng ký tài khoản CapSolver bằng cách truy cập CapSolver
-
Nạp tiền vào tài khoản CapSolver bằng PayPal, Tiền điện tử hoặc các phương thức thanh toán đã liệt kê. Lưu ý rằng số tiền nạp tối thiểu là 6 USD và các thuế bổ sung có thể áp dụng.
-
Bây giờ, sao chép khóa API do CapSolver cung cấp và lưu trữ nó an toàn để sử dụng sau này.
Giải CAPTCHA
Bây giờ, chúng ta sẽ tiến hành giải CAPTCHA bằng CapSolver. Quy trình tổng thể bao gồm ba bước:
- Khởi động trình duyệt và truy cập trang CAPTCHA bằng pyppeteer.
- Giải CAPTCHA bằng CapSolver.
- Gửi phản hồi CAPTCHA.
Đọc các đoạn mã sau để hiểu các bước này.
Khởi động trình duyệt và truy cập trang CAPTCHA:
python
# Khởi động trình duyệt.
browser = await launch({'headless': False})
# Tải trang mục tiêu.
captcha_page_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php"
page = await browser.newPage()
await page.goto(captcha_page_url)Giải CAPTCHA bằng CapSolver:
python
# Giải CAPTCHA reCAPTCHA bằng CapSolver.
capsolver = RecaptchaV2Task("YOUR_API_KEY")
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9"
task_id = capsolver.create_task(captcha_page_url, site_key)
result = capsolver.join_task_result(task_id)
# Lấy mã CAPTCHA đã được giải.
code = result.get("gRecaptchaResponse")Đặt mã CAPTCHA đã giải trên biểu mẫu và gửi nó:
python
# Đặt mã CAPTCHA đã được giải trên biểu mẫu.
recaptcha_response_element = await page.querySelector('#g-recaptcha-response')
await page.evaluate(f'(element) => element.value = "{code}"', recaptcha_response_element)
# Gửi biểu mẫu.
submit_btn = await page.querySelector('button[type="submit"]')
await submit_btn.click()Kết hợp tất cả lại với nhau
Dưới đây là mã hoàn chỉnh cho hướng dẫn, sẽ giải CAPTCHA bằng CapSolver.
python
import asyncio
from pyppeteer import launch
from capsolver_python import RecaptchaV2Task
// Mã sau giải quyết một thách thức reCAPTCHA v2 bằng CapSolver.
async def main():
// Khởi động trình duyệt.
browser = await launch({'headless': False})
// Tải trang mục tiêu.
captcha_page_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php"
page = await browser.newPage()
await page.goto(captcha_page_url)
// Giải CAPTCHA bằng CapSolver.
print("Đang giải CAPTCHA")
capsolver = RecaptchaV2Task("YOUR_API_KEY")
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9"
task_id = capsolver.create_task(captcha_page_url, site_key)
result = capsolver.join_task_result(task_id)
// Lấy mã CAPTCHA đã được giải.
code = result.get("gRecaptchaResponse")
print(f"Đã giải thành công CAPTCHA. Mã giải là {code}")
// Đặt mã CAPTCHA đã được giải trên biểu mẫu.
recaptcha_response_element = await page.querySelector('#g-recaptcha-response')
await page.evaluate(f'(element) => element.value = "{code}"', recaptcha_response_element)
// Gửi biểu mẫu.
submit_btn = await page.querySelector('button[type="submit"]')
await submit_btn.click()
// Dừng thực thi để bạn có thể xem màn hình sau khi gửi trước khi đóng trình duyệt
input("Gửi CAPTCHA thành công. Nhấn enter để tiếp tục")
// Đóng trình duyệt.
await browser.close()
if __name__ == "__main__":
asyncio.get_event_loop().run_until_complete(main())Dán đoạn mã trên vào tệp main.py của bạn. Thay thế YOUR_API_KEY bằng khóa API của bạn và chạy mã.
Bạn sẽ thấy rằng CAPTCHA sẽ được giải, và bạn sẽ được chào đón bởi trang thành công.
Cách giải CAPTCHA trong NodeJS bằng CapSolver khi trích xuất dữ liệu web
Yêu cầu tiên quyết
- Proxy (Tùy chọn)
- Node.JS đã cài đặt
- Khóa API của Capsolver
Bước 1: Cài đặt các gói cần thiết
Thực hiện các lệnh sau để cài đặt các gói yêu cầu:
python
npm install axiosMã Node.JS để giải reCaptcha v2 không dùng proxy
Dưới đây là một đoạn mã mẫu bằng Node.JS để thực hiện nhiệm vụ:
js
const axios = require('axios');
const PAGE_URL = ""; // Thay thế bằng trang web của bạn
const SITE_KEY = ""; // Thay thế bằng trang web của bạn
const CLIENT_KEY = ""; // Thay thế bằng khóa API CAPSOLVER của bạn
async function createTask(payload) {
try {
const res = await axios.post('https://api.capsolver.com/createTask', {
clientKey: CLIENT_KEY,
task: payload
});
return res.data;
} catch (error) {
console.error(error);
}
}
async function getTaskResult(taskId) {
try {
success = false;
while(success == false){
await sleep(1000);
console.log("Đang lấy kết quả nhiệm vụ cho ID nhiệm vụ: " + taskId);
const res = await axios.post('https://api.capsolver.com/getTaskResult', {
clientKey: CLIENT_KEY,
taskId: taskId
});
if( res.data.status == "ready") {
success = true;
console.log(res.data)
return res.data;
}
}
} catch (error) {
console.error(error);
return null;
}
}
async function solveReCaptcha(pageURL, sitekey) {
const taskPayload = {
type: "ReCaptchaV2TaskProxyless",
websiteURL: pageURL,
websiteKey: sitekey,
};
const taskData = await createTask(taskPayload);
return await getTaskResult(taskData.taskId);
}
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function main() {
try {
const response = await solveReCaptcha(PAGE_URL, SITE_KEY );
console.log(`Nhận được token: ${response.solution.gReCaptcharesponse}`);
}
catch (error) {
console.error(`Lỗi: ${error}`);
}
}
main();👀 Thông tin thêm
Kết luận:
Trong hướng dẫn này, chúng ta đã học cách giải CAPTCHA bằng CapSolver khi thực hiện trích xuất dữ liệu web bằng Puppeteer và Node.js. Bằng cách tận dụng API của CapSolver, chúng ta có thể tự động hóa quy trình giải CAPTCHA và làm cho các nhiệm vụ trích xuất dữ liệu web trở nên hiệu quả và đáng tin cậy hơn. Hãy nhớ tuân thủ các điều khoản và điều kiện của các trang web bạn trích xuất và sử dụng trích xuất dữ liệu web một cách có trách nhiệm.
Tuyên bố Tuân thủ: Thông tin được cung cấp trên blog này chỉ mang tính chất tham khảo. CapSolver cam kết tuân thủ tất cả các luật và quy định hiện hành. Việc sử dụng mạng lưới CapSolver cho các hoạt động bất hợp pháp, gian lận hoặc lạm dụng là hoàn toàn bị cấm và sẽ bị điều tra. Các giải pháp giải captcha của chúng tôi nâng cao trải nghiệm người dùng trong khi đảm bảo tuân thủ 100% trong việc giúp giải quyết các khó khăn về captcha trong quá trình thu thập dữ liệu công khai. Chúng tôi khuyến khích việc sử dụng dịch vụ của chúng tôi một cách có trách nhiệm. Để biết thêm thông tin, vui lòng truy cập Điều khoản Dịch vụ và Chính sách Quyền riêng tư.
Thêm

Cách giải CAPTCHA trên Nanobot bằng CapSolver
Tự động hóa việc giải CAPTCHA với Nanobot và CapSolver. Sử dụng Playwright để giải reCAPTCHA và Cloudflare tự động.
Anh Tuan
26-Feb-2026

Dữ liệu dưới dạng dịch vụ (DaaS): Nó là gì và tại sao nó quan trọng vào năm 2026
Hiểu về Dịch vụ Dữ liệu (DaaS) vào năm 2026. Khám phá lợi ích, trường hợp sử dụng và cách nó thay đổi doanh nghiệp với phân tích thời gian thực và tính mở rộng.

Emma Foster
12-Feb-2026

Cách sửa các lỗi thu thập dữ liệu web phổ biến vào năm 2026
Nắm vững việc sửa chữa các lỗi trình gỡ mã web đa dạng như 400, 401, 402, 403, 429, 5xx, và Cloudflare 1001 vào năm 2026. Học các chiến lược tiên tiến về chuyển đổi IP, tiêu đề, và giới hạn tốc độ thích ứng với CapSolver.

Nikolai Smirnov
05-Feb-2026

Cách khắc phục bảo vệ Cloudflare khi quét web
Học cách giải quyết bảo vệ Cloudflare khi quét dữ liệu web. Khám phá các phương pháp đã được chứng minh như xoay đổi IP, tinh vân TLS và CapSolver để xử lý các thách thức.
Nikolai Smirnov
05-Feb-2026

Cách giải Captcha trong RoxyBrowser với tích hợp CapSolver
Tích hợp CapSolver với RoxyBrowser để tự động hóa các nhiệm vụ trình duyệt và vượt qua reCAPTCHA, Turnstile và các CAPTCHA khác.
Anh Tuan
04-Feb-2026

Cách giải reCAPTCHA v2 trong Relevance AI với tích hợp CapSolver
Xây dựng một công cụ AI của Relevance để giải quyết reCAPTCHA v2 bằng CapSolver. Tự động hóa việc gửi biểu mẫu qua API mà không cần tự động hóa trình duyệt.
Anh Tuan
03-Feb-2026